
sign language
제작동기
청각장애인을 위한 인공지능
인공지능 기술이 급속도로 발전하고 있는 현재, 이를 활용하여 일상생활에 불편을 느끼는 장애인 분들을 위한 제품을 만들어 보고 싶었다. 그 중 청각장애인을 위한 수화인식 프로그램을 만들면 좋겠다고 생각하게 되었다.
MediaPipe 라이브러리를 사용하여 손의 joint를 검출한다. 그 출력 결과를 단일 동작으로 분류 할 수 있는 KNN(K-Nearest Neighbor)과 연속 동작을 분류 할 수 있는 RNN(Recurrent Neural Network)의 입력으로 학습하여 지화를 실시간으로 인식하고 출력한다.
이론적 배경
MediaPipe
MediaPipe란 구글에서 제공하는 AI 프레임워크로써, 비디오 형식 데이터를 이용한 다양한 비전 AI기능을 파이프라인 형태로 손쉽게 사용할 수 있도록 제공된다. AI 모델 개발 및 수많은 데이터셋을 이용한 학습도 마친 사태로 제공되므로 라이브러리를 불러 사용하듯이 간편하게 호출하여 사용하기만 하면 되는 형태로, 비전 AI 기능을 개발 할 수 있다.

 다음과 같이 손을 인식하여 준다. 이때 빨간점으로 표시된 마디(joint)를 사용하여 벡터를 만들고, 그 벡터들 사이의 각도를 이용해서 손 모양을 학습시킬 수 있다.
다음과 같이 손을 인식하여 준다. 이때 빨간점으로 표시된 마디(joint)를 사용하여 벡터를 만들고, 그 벡터들 사이의 각도를 이용해서 손 모양을 학습시킬 수 있다.
KNN(K-Nearest Neighbor)
knn은 최근접 이웃 알고리즘으로 지도학습 알고리즘 중 하나이다.
- 지도학습 : 여러 문제와 답을 같이 학습함으로써 미지의 문제애 대한 올바른 답을 예측하고자 하는 방법이다. 따라서 지도학습에는 문제와 함께 그 정답까지 알고있는 데이터가 제공되어야 한다.
- 비지도학습 : 지도학습과는 달리 정답 라벨이 없는 데이터를 비슷한 특징끼리 군집화 하여 새로운 데이터에 대한 결과를 예측하는 방법이다.
새로운 데이터를 입력 받았을때, 해당 데이터와 가장 가까이에 있는 k개의 데이터를 확인해, 새로운 데이터의 특성을 파악하는 방법이다.
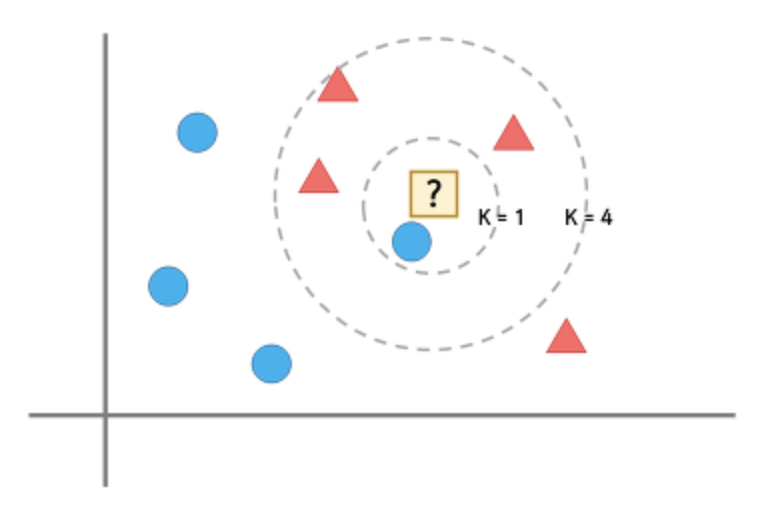
위 그림에서 ‘?’의 주변에 가장 가깝고 많이 있는것이 무엇인가 를 확인하여 ‘?’가 삼각형인지 원인지 판별하는 것이다.
- K가 1일경우 ‘?’주변에는 가장 가깝고 많이 있는것은 원 하나이므로 ‘?’는 원으로 판별한다.
- K가 4일 경우 ‘?’주변에 가장가깝고 많이 있는것은 삼각형이므로 ‘?’는 삼각형으로 판별한다.
그러면 K는 몇으로 설정하는게 가장 좋을까?
- k가 낮다 → 적은 이웃 수로 판단한다 → 불안정한 결과
-
k가 높다 → 많은 이웃 수로 판단한다 → 지나친 일반화
- 가장 좋은 성능을 내는 k를 선택
- k의 값을 1부터 증가시켜가며 각 점들에 대해 knn으로 분류해보고 오류 계산
- 가장 오류가 적은 k값을 선택
RNN
RNN은 음성, 문자와 같이 순차적으로 진행하는 데이터 처리에 적합한 알고리즘 이다.
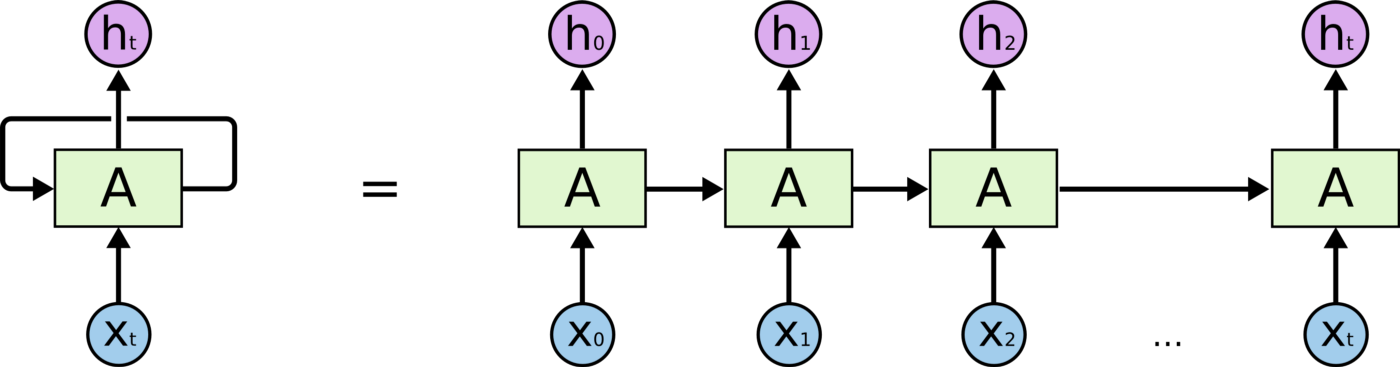
그림과 같이 hidden layer의 결과가 다시 hidden layer의 입력으로 들어가는 순환되는 구조를 가졌기 때문에 재귀 인공 신경망이라고 불린다.
hidden layer의 결과가 다시 hidden layer의 입력으로 들어가는 특성 때문에 RNN은 현재 들어오는 입력 데이터와 전 단계에서 나온 결과를 동시에 고려하게 됨으로써 기억 능력이 있다고 할 수 있게 되고, sequence 또는 시계열 데이터를 분석하는데 굉장이 효과적인 네트워크이다.
구현 과정
1. media pipe가 제공해 주는 손의 joint를 활용하여 벡터사이의 각도를 구한다.
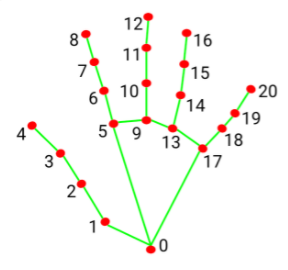
1️⃣ 점과 점사이의 뺄셈 연산을 통해 0번에서 1번으로 가는 벡터, 1번에서 2번으로 가는 벡터 등등 많은 벡터를 만들어낸다.
if result.multi_hand_landmarks:
for hand_landmarks in result.multi_hand_landmarks: # 여러개의 손을 인식 할 수 있으니까, for문 반복
joint = np.zeros((21,4)) # 손 관절 (joint) 넘파이 배열로 생성
for j, lm in enumerate(hand_landmarks.landmark): # media pipe의 landmark를 반복하며 joint에 대입
joint[j] = [lm.x,lm.y,lm.z,lm.visibility]
v1 = joint[[0,1,2,3,0,5,6,7,0, 9,10,11, 0,13,14,15, 0,17,18,19],:3] # 벡터를 구하기 위해 생성하는 v1,v2 (v2에서 v2을 빼면 v백터가 된다)
v2 = joint[[1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20],:3]
v = v2-v1
v = v / np.linalg.norm(v,axis=1)[:,np.newaxis] # 정규화
2️⃣ 만들어진 벡터들 사이의 각도를 구한다
compareV1 = v[[0,1,2,4,5,6,8,9,10,12,13,14,16,17,18],:] #각 벡터의 각도를 비교하기 위해 생성하는 compare벡터
compareV2 = v[[1,2,3,5,6,7,9,10,11,13,14,15,17,18,19],:]
angle = np.arccos(np.einsum('nt,nt->n',compareV1,compareV2)) # compare벡터를 사용하여 각도를 구함
angle = np.degrees(angle)
3️⃣ 손 모양에 따른 데이터셋 파일을 write한다
if keyboard.is_pressed('a'): # gesture를 학습하기 위한 조건문(a키를 누르고 있으면 각도와 라벨이 test.txt에 write됨)
for num in angle:
num = round(num,6)
f.write(str(num))
f.write(',')
f.write("25.000000") # 학습하고자 하는 손 동작의 라벨
f.write('\n')
print('next')
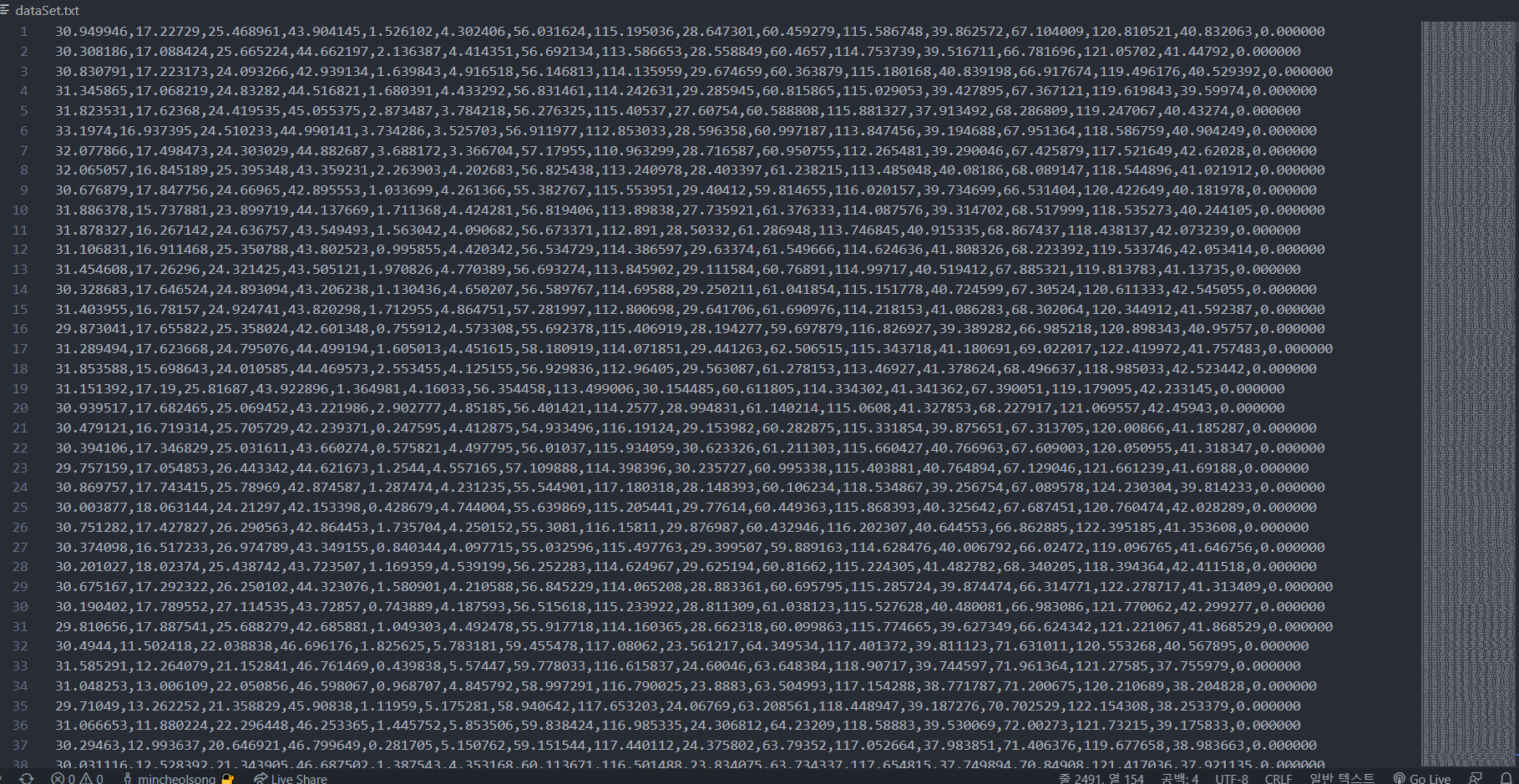
데이터 셋을 구하는 코드이다. 키보드 ‘a’키를 누르고 있으면 test.txt파일에 현재 각도와 손 동작의 라벨이 write된다.
이렇게 손 동작 하나하나에 대해서 구한 정보를 dataSet.txt파일에 붙여넣어 데이터셋을 완성하였다.
2-1. 구해진 각도와 KNN 을 사용하여 정적인 손동작을 학습시킨다.
data = np.array([angle],dtype=np.float32)
ret, results, neighbours, dist = knn.findNearest(data,3) #knn알고리즘 적용
구한 angle을 numpy 형태 데이터로 만들고, 그 데이터에 knn을 사용하여 학습시키는 코드이다.
수행결과

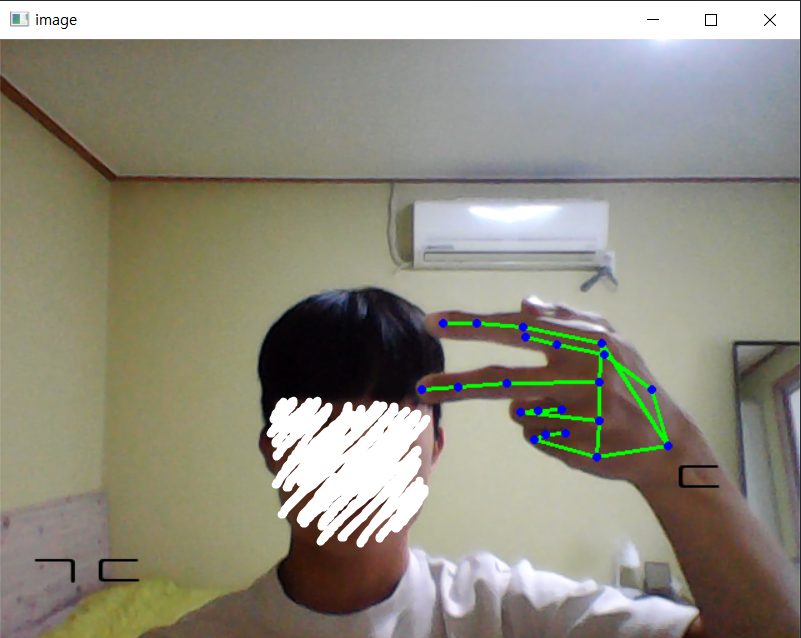 그림과 같이 손동작에 따른 자음이 잘 출력되었다.
그림과 같이 손동작에 따른 자음이 잘 출력되었다.
2-2. ‘done’동작을 취하면 입력한 초성으로 시작하는 단어목록을 출력하여 준다
gesture = {
0:'ㄱ',1:'ㄴ',2:'ㄷ',3:'ㄹ',4:'ㅁ',5:'ㅂ',6:'ㅅ',7:'ㅇ',
8:'ㅈ',9:'ㅊ',10:'ㅋ',11:'ㅌ',12:'ㅍ',13:'ㅎ', 25:'done',26:'spacing',27:'clear'
}
complete = 0 # 글씨 입력을 완료 했는지 확인하는 변수(done 동작을 하면 1로 바꿈)
.
.
.
if index == 25: # done동작(25위에서 읽은 dic_file에서 sentce검색하고, 그 위치의 단어를 출력
for i in range(0, dic_file.[0]):
if (sentence == dic['초성'][i]):
selected_words.append(dic_file['단어'][i])
complete=1 #complete 를 위해 1로 변경한다
i=0
word=''
elif complete==0 and index!=27index!=26:
sentence += gesture[index]
startTime = time.time()
if complete==0:
word = gesture[index]
draw.text((int(hand_landmarks.landmar x*image.shape[1]),int(hand_landm landmark[0].y*image.shape[0])), word, font=font, fill=(255,255,255))
draw.text((20,400),sentence,font=font,fill=(255,255,255))
if complete==1:
print(sentence)
print(selected_words)
.
.
.
25번 동작, 즉 done을 하면 dic에서 입력한 초성을 검색하고, selected_words에 append한다.
그 다음 일종의 flag변수역할을 하는 complete를 1로 변경시킨다.
(이렇게 하는 이유는 done동작을 했을 경우 분기점을 만들어 다른 조건문이 실행되도록 하기 위함이다.)
3.RNN의 LSTM을 사용하여 동적인 손동작(next, prev)을 학습
3-1.window를 생성
RNN의 LSTM을 사용하여 동적인 동작을 학습시키는 과정도 벡터사이의 각도를 이용한다. 하지만 window라는 것을 만들어야 하는데 이것은 LSTM의 기본 개념인 최근 ~개의 데이터를 가지고 다음 데이터를 예측하기 위해서이다.
seq_length = 30
seq_length=30, 즉 window 사이즈를 30으로 설정하였다.
(최근 30개의 데이터를 보고 다음 데이터를 예측하게 된다)
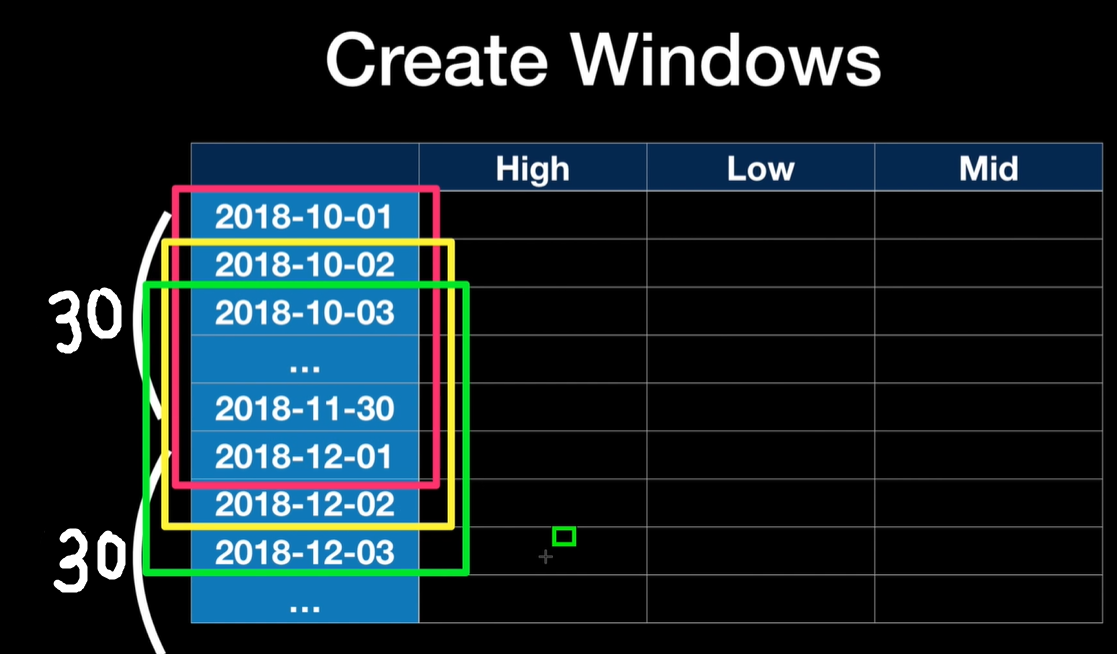
사진출처 : 빵형의 개발도상국 유튜브
위 그림에서 보는것 처럼 빨간색 window를 만들고 그 다음 한칸씩 내려가면서 window를 계속 만든다.
(노란색 window를 만들고, 초록색 window …)
full_seq_data = []
for seq in range(len(data) - seq_length):
full_seq_data.append(data[seq:seq + seq_length])
full_seq_data = np.array(full_seq_data)
np.save(os.path.join('dataset', f'seq_{action}_{created_time}'), full_seq_data)
그 다음 for문을 돌면서 full_seq_data라는 리스트에 30개의 한 스텝씩 넘어가면서 데이터를 저장하여 sequence dataSet파일을 만든다.
3-2.dataSet파일을 사용하여 train
actions = [
'prev',
'next',
'stop'
]
data = np.concatenate([
np.load('dataset/seq_prev_1653293844.npy'),
np.load('dataset/seq_next_1653293844.npy'),
np.load('dataset/seq_stop_1653293844.npy'),
], axis=0)
액션을 3개로 정의해주고, 위에서 만든 dataSet을 전부 load 후 하나로 합쳐준다.
x_data = data[:, :, :-1]
labels = data[:, 0, -1]
라벨과 데이터를 분리하여 준다.
그 다음 라벨을 Categorical data로 만들어 주기 위해 One-Hot Encoding을 해야 한다.
One-Hot Encoding이란 사람이 이해하는 데이터를 컴퓨터에게 주입시키기 위한 가장 기본적인 방법이라고 할 수 있다.
데이터를 수 많은 0과 한 개의 1 값으로 구분한다. 예를들어 숫자 0부터 9까지 구분하려 한다면[1,0,0,0...0][0,1,0,0...0][0,0,1,0...0]...[0,0,0,0...1]이렇게 인코딩하는 것이다.
from tensorflow.keras.utils import to_categorical
y_data = to_categorical(labels, num_classes=len(actions))
print(y_data.shape)
tensorflow keras의 to_categorical을 사용하여 One-Hot Encoding을 적용하였다.
from sklearn.model_selection import train_test_split
x_data = x_data.astype(np.float32)
y_data = y_data.astype(np.float32)
x_train, x_val, y_train, y_val = train_test_split(x_data, y_data, test_size=0.1, random_state=2021)
sklearn의 train_test_split을 사용해서 training set과 test set으로 나눠준다. training set은 90%, test set은 10% 로 나눠준다.
training set(학습 데이터셋) : 모델의 학습을 위해 사용되는 데이터이다.
test set(테스트 데이터셋) : 생성된 모델의 예측성능을 평가하는데 사용된다.
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import LSTM, Dense
model = Sequential([
LSTM(64, activation='relu', input_shape=x_train.shape[1:3]),
Dense(32, activation='relu'),
Dense(len(actions), activation='softmax')
])
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['acc'])
model.summary()
모델을 정의하는 코드이다.
Sequential API를 사용하여 LSTM과 DENSE 두개를 연결하여 준다. LSTM의 노드 갯수는 64개 activation 은 relu를 사용, Dense의 노드 갯수는 32개 activation은 relu를 사용한다. 그리고 activation은 softmax를 사용한다.
loss는 categorical_crossentropy를 사용하여 3개의 동작 중 어떤것인가를 model한테 추론하게 한다.
history = model.fit(
x_train,
y_train,
validation_data=(x_val, y_val),
epochs=200,
callbacks=[
ModelCheckpoint('models/model.h5', monitor='val_acc', verbose=1, save_best_only=True, mode='auto'),
ReduceLROnPlateau(monitor='val_acc', factor=0.5, patience=50, verbose=1, mode='auto')
]
)
최종적으로 학습을 시키는 과정이다.
순서도
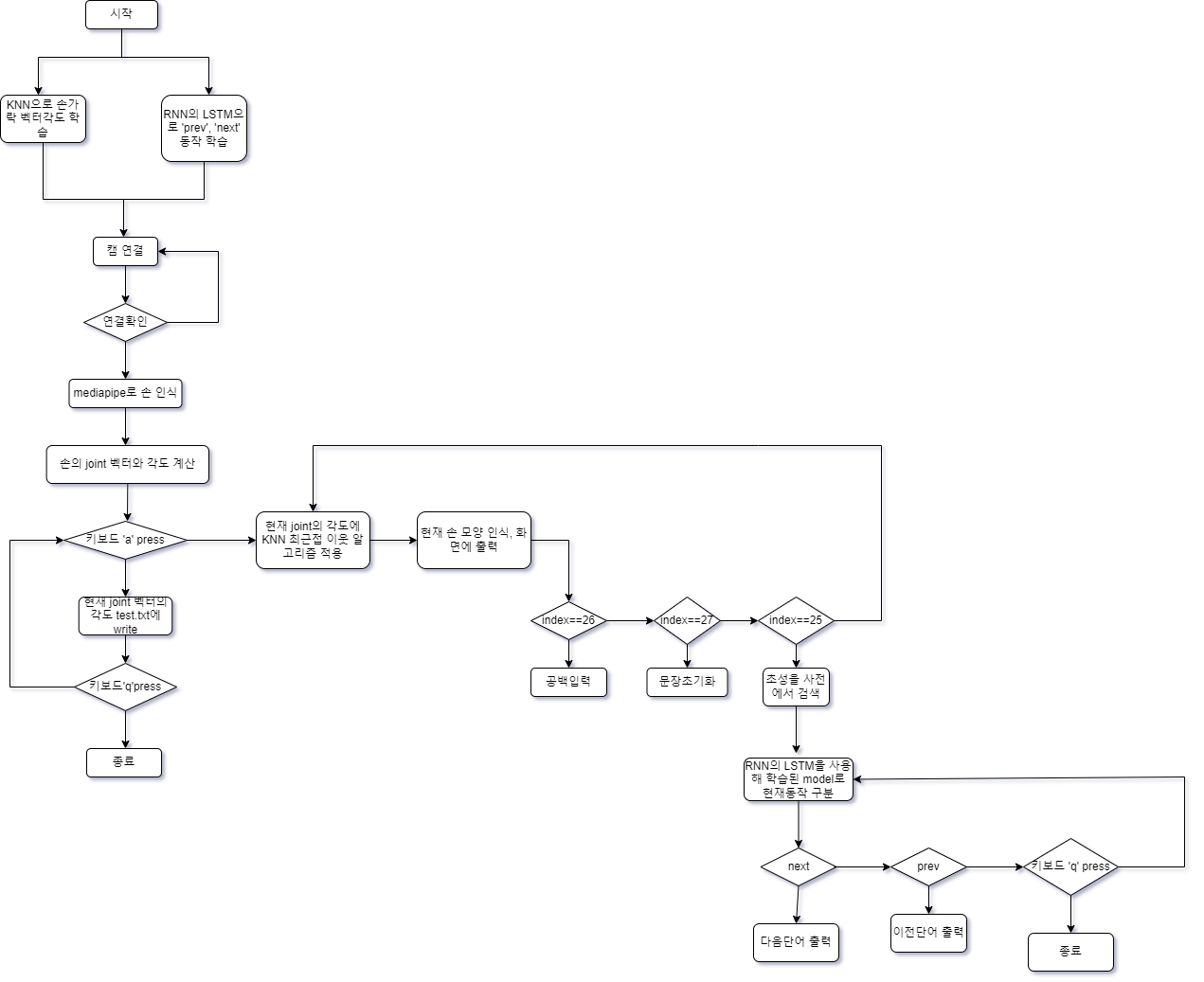
수행결과
참조
유튜브 ‘빵형의 개발도상국’
👇
빵형의 개발도상국
한계
양손을 사용하여 동적인 동작이 많은 수화를 학습시키는 것에 어려움을 느껴, 수화의 한 종류인 지화를 구현하였다. 그리고 지화를 통해 한정된 단어를 번역하는것에 그쳤다.
개선하고 싶은점
모음의 지화를 추가하여, 자음과 모음을 조합할 수 있는 기능을 만들면 지금보다는 더 완성도 있는 프로그램이 될 것 같다.
느낀점
파이썬이 서툴었고, 딥러닝도 처음이었다. 꽤 오랜기간 동안 구글 유튜브 등을 찾아보며 어떻게든 해내고자 하였다. 프로젝트를 진행하며 대략적인 딥러닝의 개념을 알 수 있었다. 완벽하진 않지만 딥러닝을 사용해봤다는 점과 결과물을 만들어 냈다는 점에 의의를 두고 싶다.👏
[전체코드 : 캡스톤경진대회 시연을 위해 gui를 추가한 코드]
댓글남기기